几款开源的OCR识别项目,收藏备用
随着科技的发展,OCR场景随处可见,很多APP也集成如身份证识别,银行卡识别的功能,包括微信都支持截图文件中的文字提取。现在,各大厂商均有提供各种场景的OCR识别的API。但是,有时候我们也想自己来折腾一下。这时候,就可以借助一些主流开源框架来快速达到我们的目的。
OCR引擎
tesseract
Tesseract,一款由HP实验室开发由Google维护的开源OCR引擎,开源,免费,支持多语言,多平台;
https://github.com/tesseract-ocr/tesseract.git
tesseract.js
js版本的Tesseract OCR,支持一百多种语言,使用也是非常简单,可以用npm安装,也可以直接在页面引用js
https://github.com/naptha/tesseract.js.git
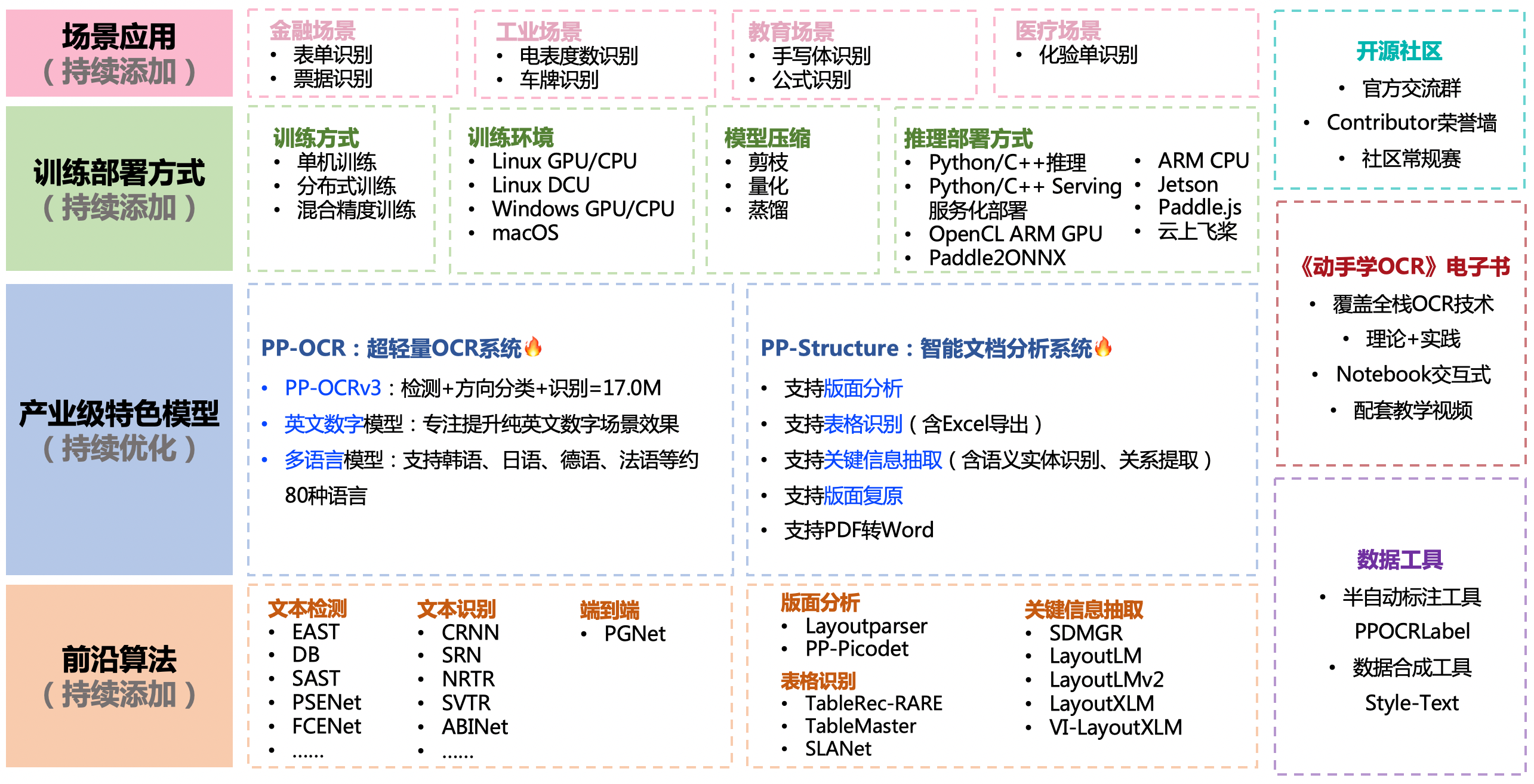
PaddleOCR
PaddleOCR是百度开源一套OCR,旨在打造一套丰富、领先、且实用的OCR工具库,助力开发者训练出更好的模型,并应用落地。

https://github.com/PaddlePaddle/PaddleOCR.git
EasyOCR
EasyOCR是用Python编写基于Tesseract的OCR识别库,用于图像识别输出文本,目前支持80多种语言。
https://github.com/JaidedAI/EasyOCR.git
mmocr
MMOCR 是基于 PyTorch 和 mmdetection 的开源工具箱,专注于文本检测,文本识别以及相应的下游任务,如关键信息提取。
https://github.com/open-mmlab/mmocr.git
simple-ocr-opencv
基于opencv 和numpy开源的OCR识别引擎
https://github.com/goncalopp/simple-ocr-opencv.git
OCR工具
OCRmyPDF
OCRmyPDF是基于tesseract-ocr开发、训练的文字识别提取的开源项目
https://github.com/ocrmypdf/OCRmyPDF.git
Umi-OCR
基于 PaddleOCR 实现的一款开源的文字识别工具,
一般开源项目,识别率肯定没有商用的那么高,只有通过训练自己的字库来提高识别率。文字识别场景,有时候就会涉及到图片处理,这里又会关联到其它强大的图像处理开源项目,如:OpenCV。这些项目中,PaddleOCR相对来说会更符合我们常见的业务场景,也支持我们自己去训练。
几款开源的OCR识别项目,收藏备用