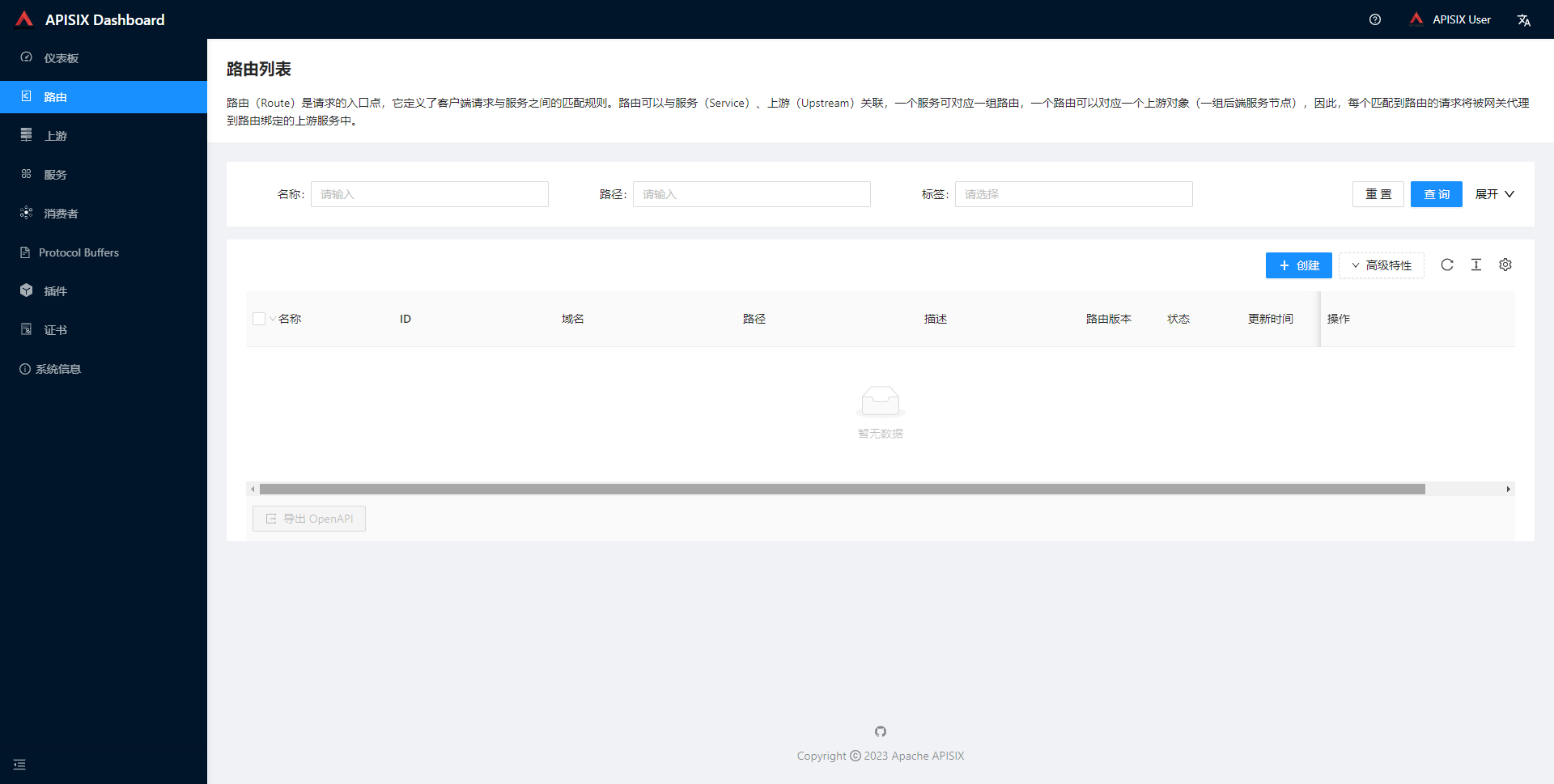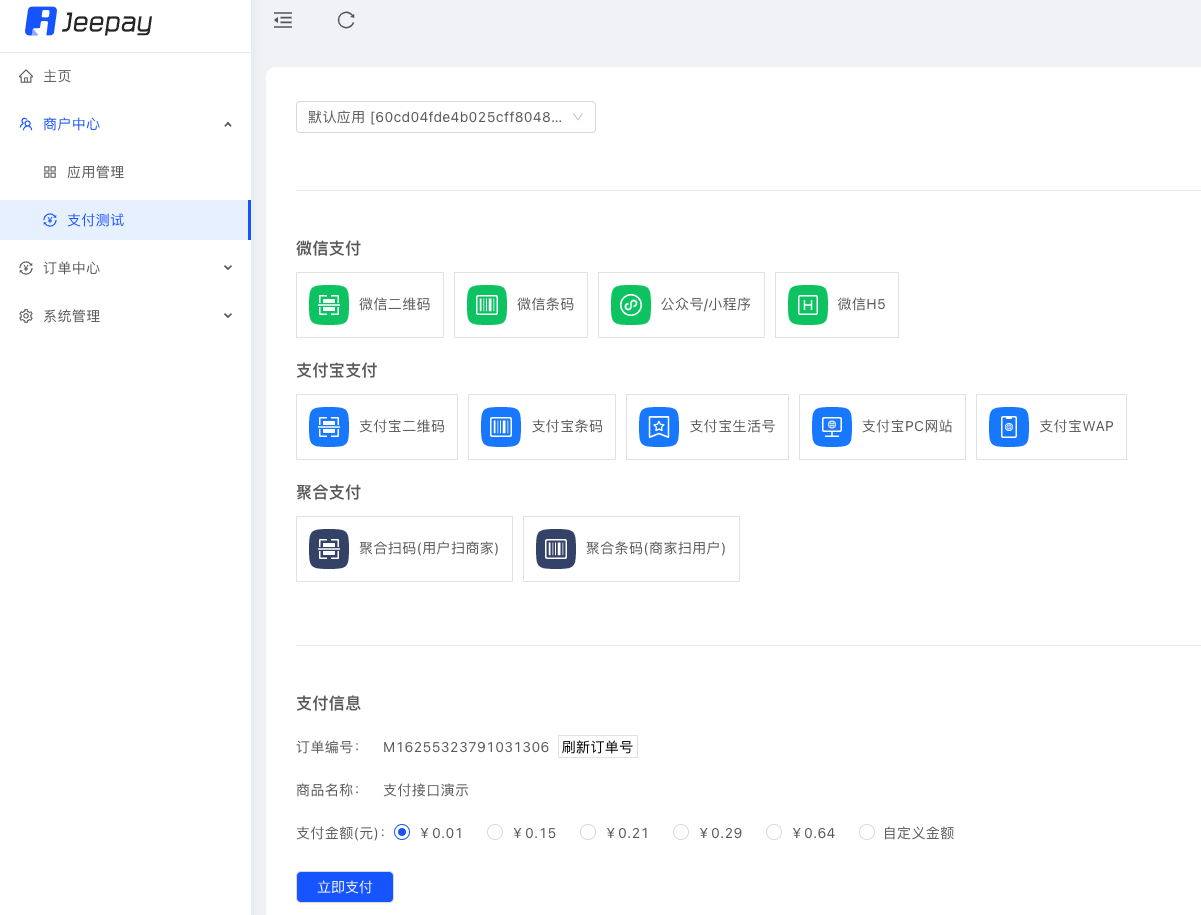
移动支付随处可见,以前都是微信、支付宝分别各一个收款码,二维码多了之后就不好管理了,随着支付方式的增多,现在基本上都用聚合支付,多种支付方式,一码搞定。针对支付及聚合支付,开源社区也有很多相关的开源项目。
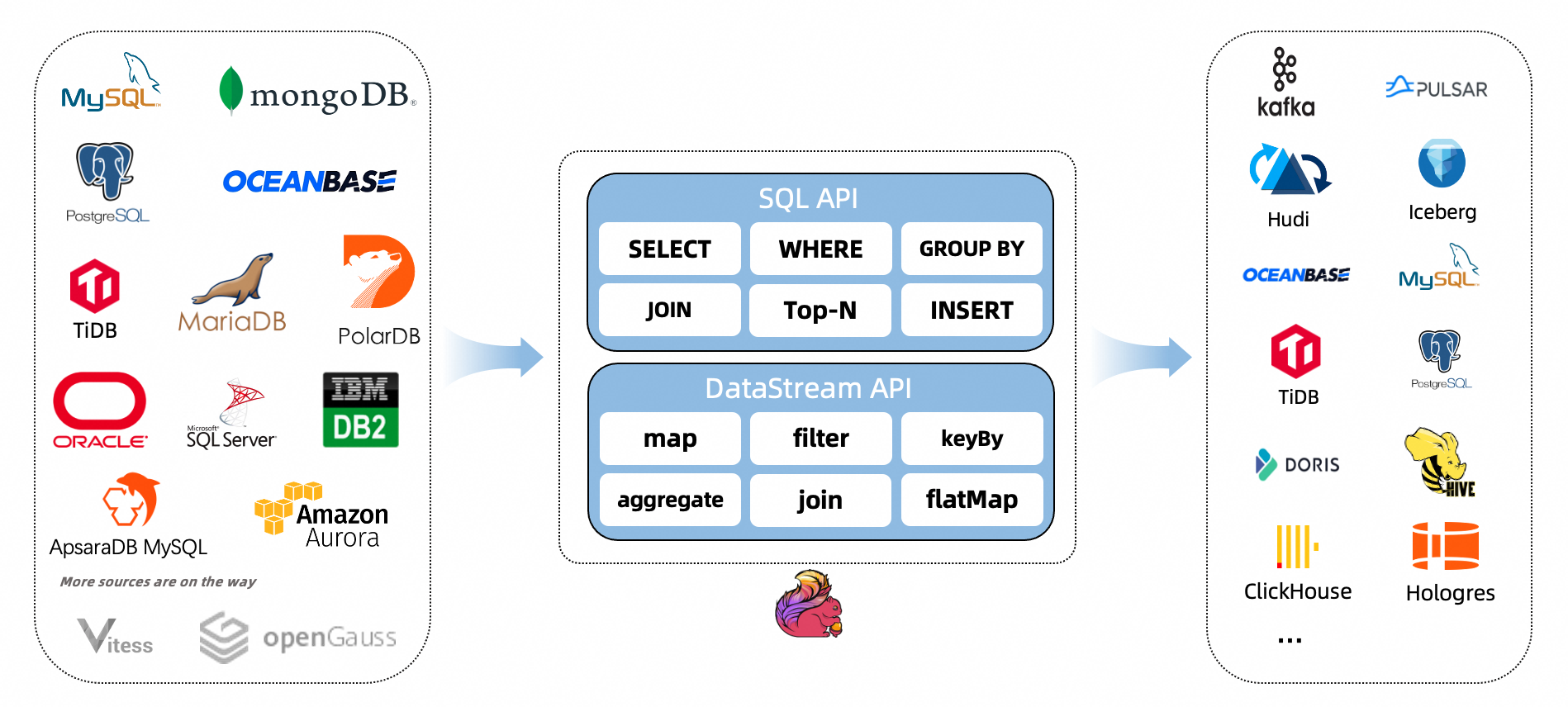
异构跨库数据同步还在用Datax?来看看这几个开源的同步方案
在遇到跨库或者异库数据同步时,我们一般都会借助ETL工具来实现数据同步功能。比如目前大家较为熟知的Kettle和Datax。但是,这两个需要定时去查询数据库的数据,会存在一定的延迟,而且,默认采用全量同步的方式,想要增量,需要自己做特殊的处理。那么,有没有开源的工具,既能满足全量和增量,又能达到相对比较实时的呢?接下来,我们继续往下看。
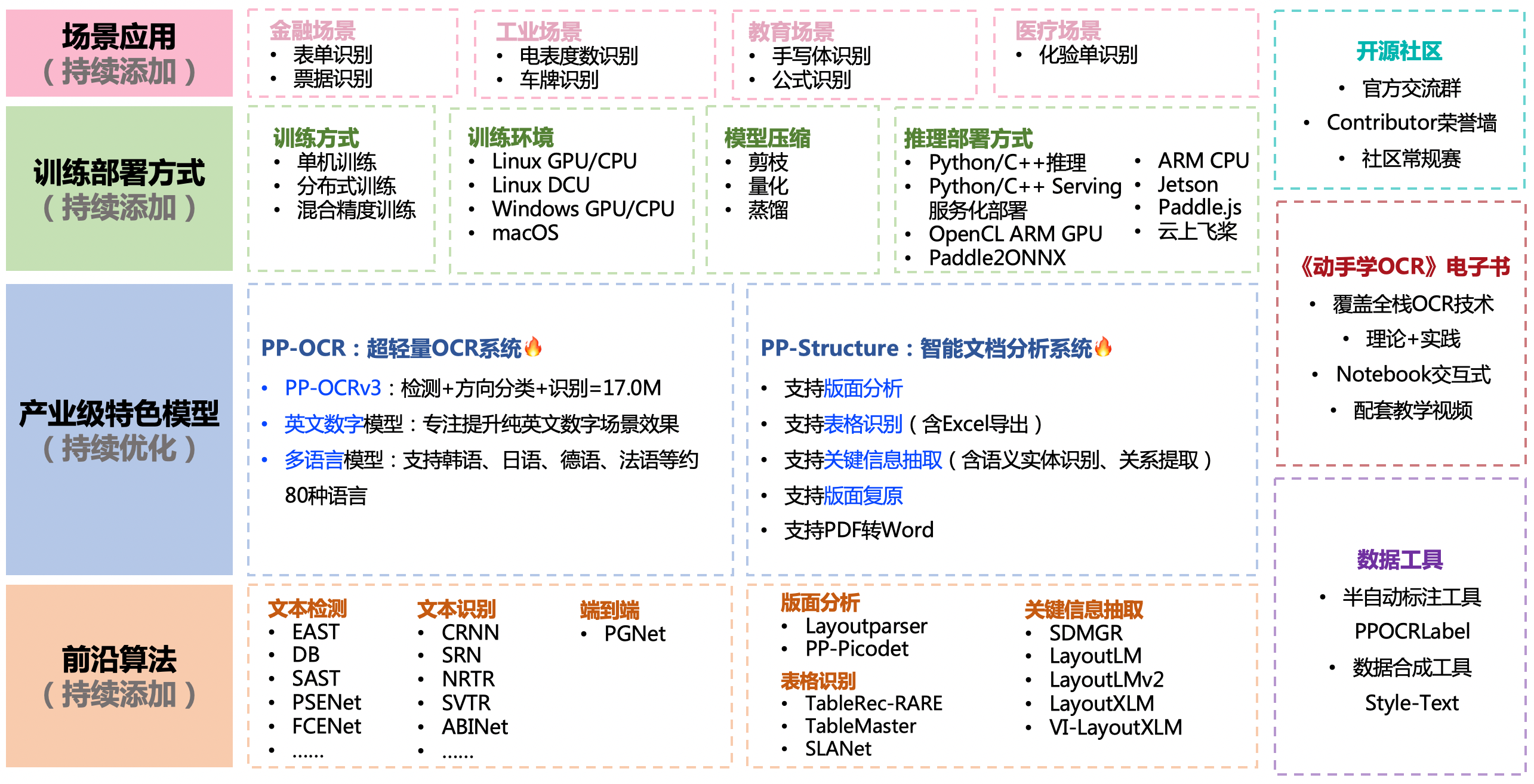
几款开源的OCR识别项目,收藏备用
随着科技的发展,OCR场景随处可见,很多APP也集成如身份证识别,银行卡识别的功能,包括微信都支持截图文件中的文字提取。现在,各大厂商均有提供各种场景的OCR识别的API。但是,有时候我们也想自己来折腾一下。这时候,就可以借助一些主流开源框架来快速达到我们的目的。
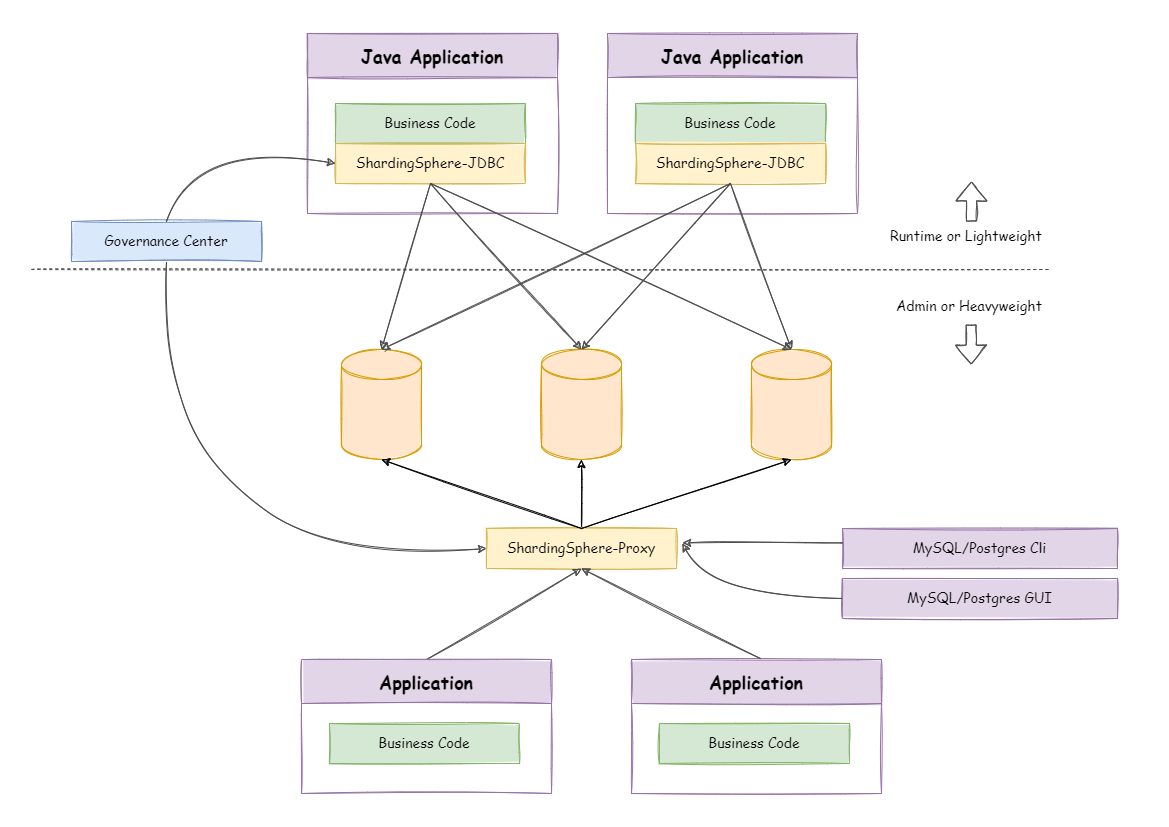
这些开源的分库分表中间件,你们都知道吗?
当我们的数据达到一定的量级之后,单表甚至单库都无法支撑之时,那么,便会涉及到分库分表。分库分表的方式有多种,开源的解决方案也很多,都是围绕客户端和代理两种模式来处理的。
Tempo实现分布式链路追踪
提到链路追踪,大家肯定能想到众多的开源解决方案,如:SkyWalking、Zipkin、Pinpoint、CAT、Jaeger等等,如果要构建完整的平台,我会选择SkyWalking,但是,条件不足啊。所以,这里便使用开源的Tempo基于Loki来构建一个简单的链路追踪系统。
这些开源的后台管理系统,随便用,私活必备
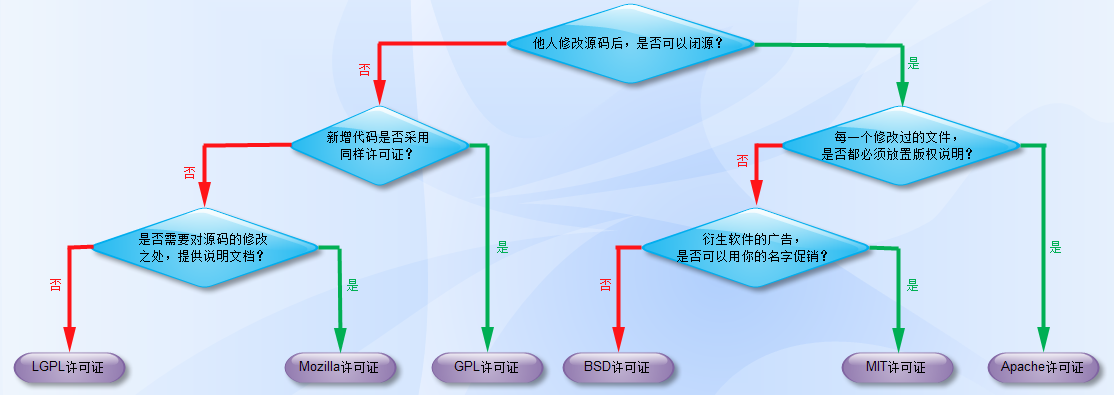
开源项目何其之多,但是在使用时,我还是要注意开源协议,避免必要的麻烦。有时候,我们可以根据情况来选在合适的开源项目,今天就整理了MIT License的一些项目,关于开源协议,大家可以看看这张图片
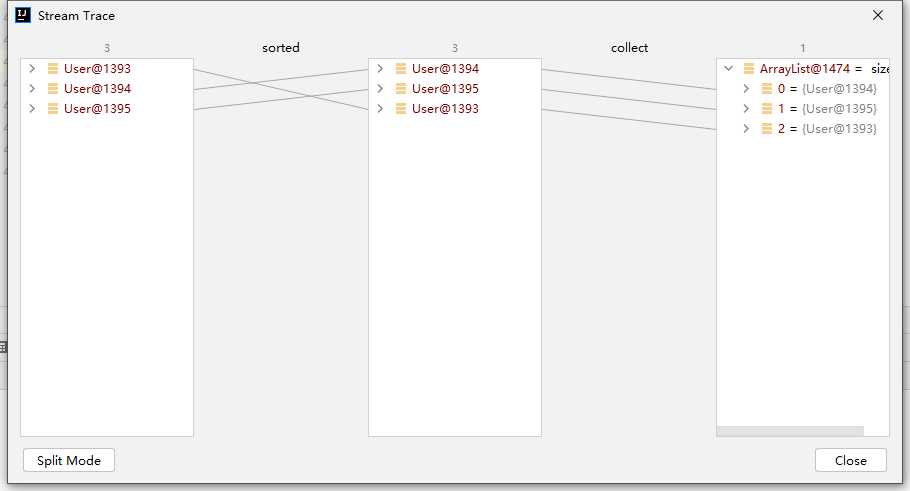
Java8 中常用的List Stream场景
Stream是Java 8添加的一个API,结合Lambda表达式,可以提高我们对对集合处理的编码效率。在日常工作中,我们经常会遇到List转Map的情况,在Stream出来之前,我们一般都是遍历放进map中。