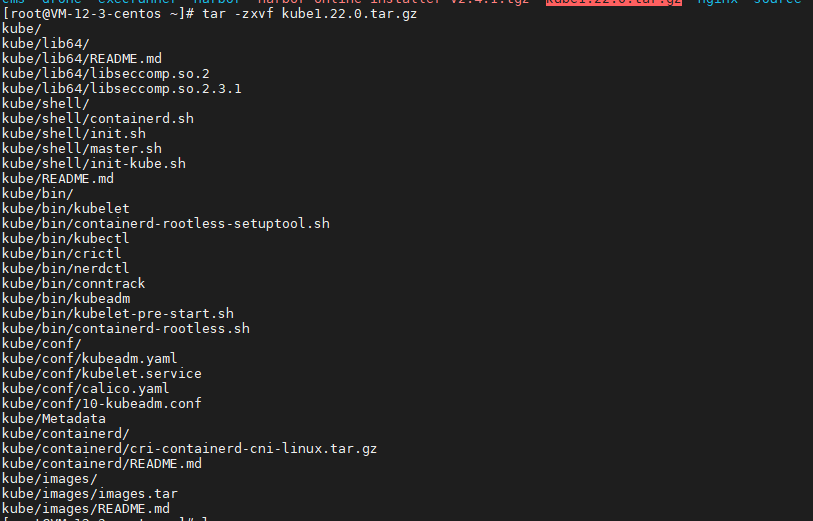
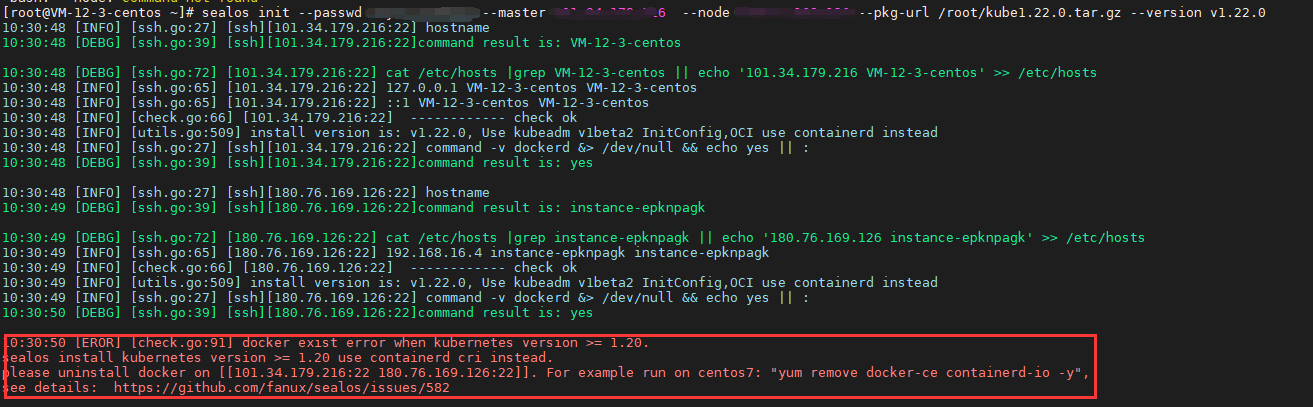
[root@VM-12-3-centos ~]# sealos A longer description that spans multiple lines and likely contains examples and usage of using your application. For example:
Cobra is a CLI library for Go that empowers applications. This application is a tool to generate the needed files to quickly create a Cobra application.
Usage: sealos [command]
Available Commands: cert generate certs clean Simplest way to clean your kubernets HA cluster cloud sealos on cloud cni A brief description of your command completion Output shell completion code for the specified shell (bash or zsh) config print config template to console delete delete kubernetes apps installled by sealos.. etcd Simplest way to snapshot/restore your kubernets etcd exec support exec cmd or copy file by Label/nodes help Help about any command init Simplest way to init your kubernets HA cluster install install kubernetes apps, like dashboard prometheus .. ipvs sealos create or care local ipvs lb join Simplest way to join your kubernets HA cluster route set default route gateway upgrade upgrade your kubernetes version by sealos version Print the version of sealos
Flags: --config string config file (default is $HOME/.sealos/config.yaml) -h, --help help for sealos --info logger ture for Info, false for Debug
Use "sealos [command] --help" for more information about a command.
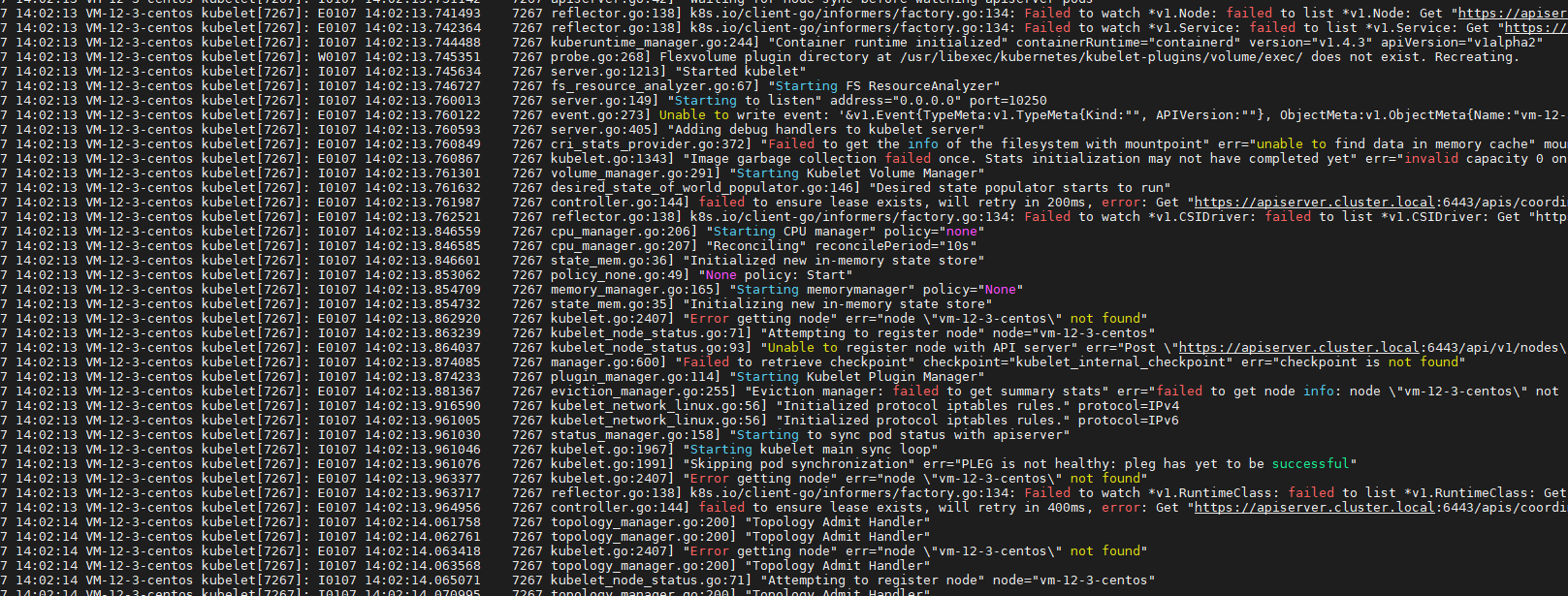
Unfortunately, an error has occurred: timed out waiting for the condition
This error is likely caused by: - The kubelet is not running - The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands: - 'systemctl status kubelet' - 'journalctl -xeu kubelet'
Additionally, a control plane component may have crashed or exited when started by the container runtime. To troubleshoot, list all containers using your preferred container runtimes CLI.
Here is one example how you may list all Kubernetes containers running in cri-o/containerd using crictl: - 'crictl --runtime-endpoint /run/containerd/containerd.sock ps -a | grep kube | grep -v pause' Once you have found the failing container, you can inspect its logs with: - 'crictl --runtime-endpoint /run/containerd/containerd.sock logs CONTAINERID'
error execution phase wait-control-plane: couldn't initialize a Kubernetes cluster To see the stack trace of this error execute with --v=5 or higher
我用journalctl -r kubelet去看了一下日志,
发现一句modprobe: FATAL: Module nf_conntrack_ipv4 not found in directory /lib/modules/4.18.0-305.3.1.el8.x86_64,因为我的内核版本有些高,nf_conntrack_ipv4被nf_conntrack替换了,所以需要设置一下modprobe -- nf_conntrack,此时,端口10259(kube-cont)和10257(kube-sche)已经占用,我们需要通过lsof -i tcp:10259去找到进程并杀掉,然后重新初始化